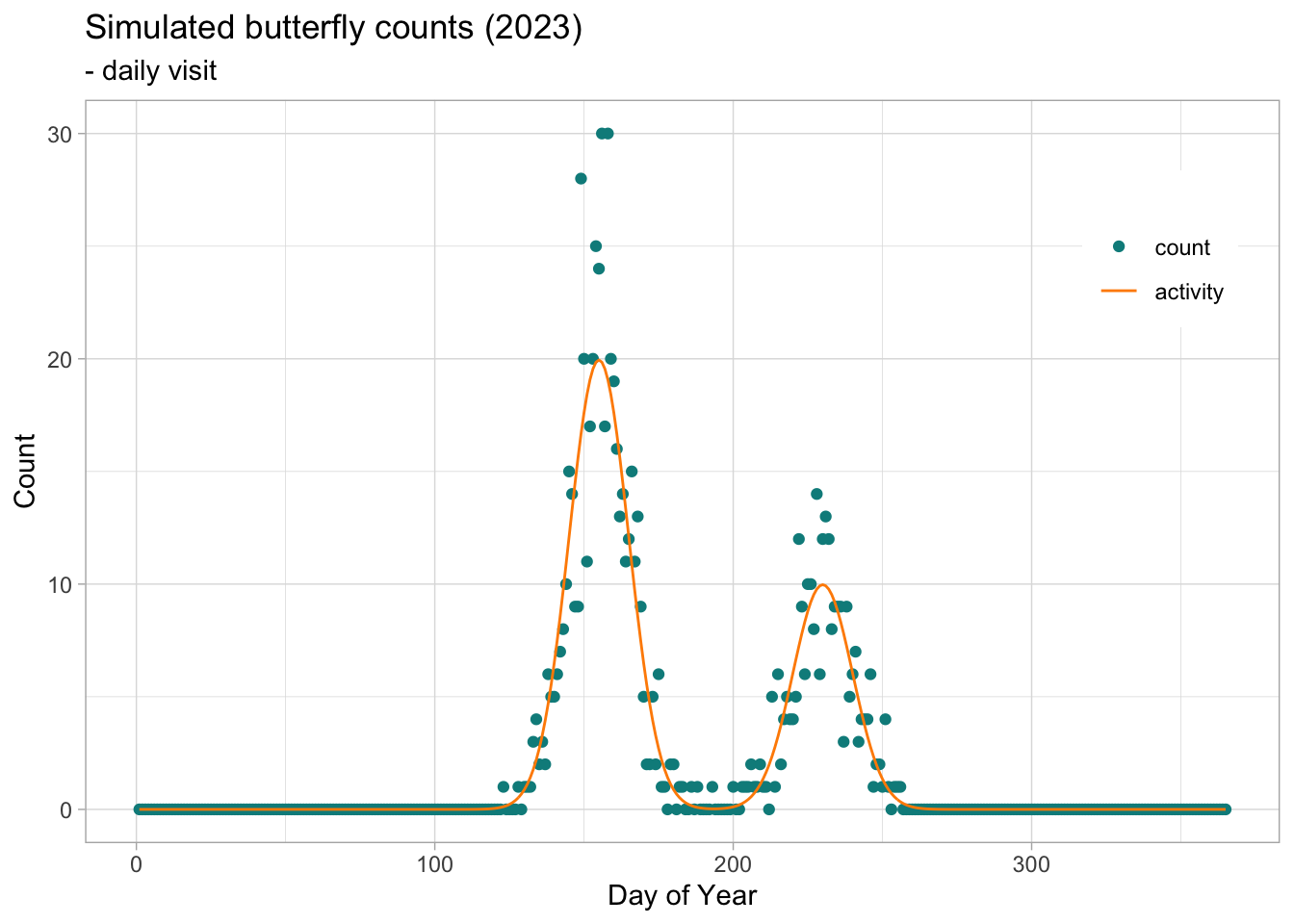
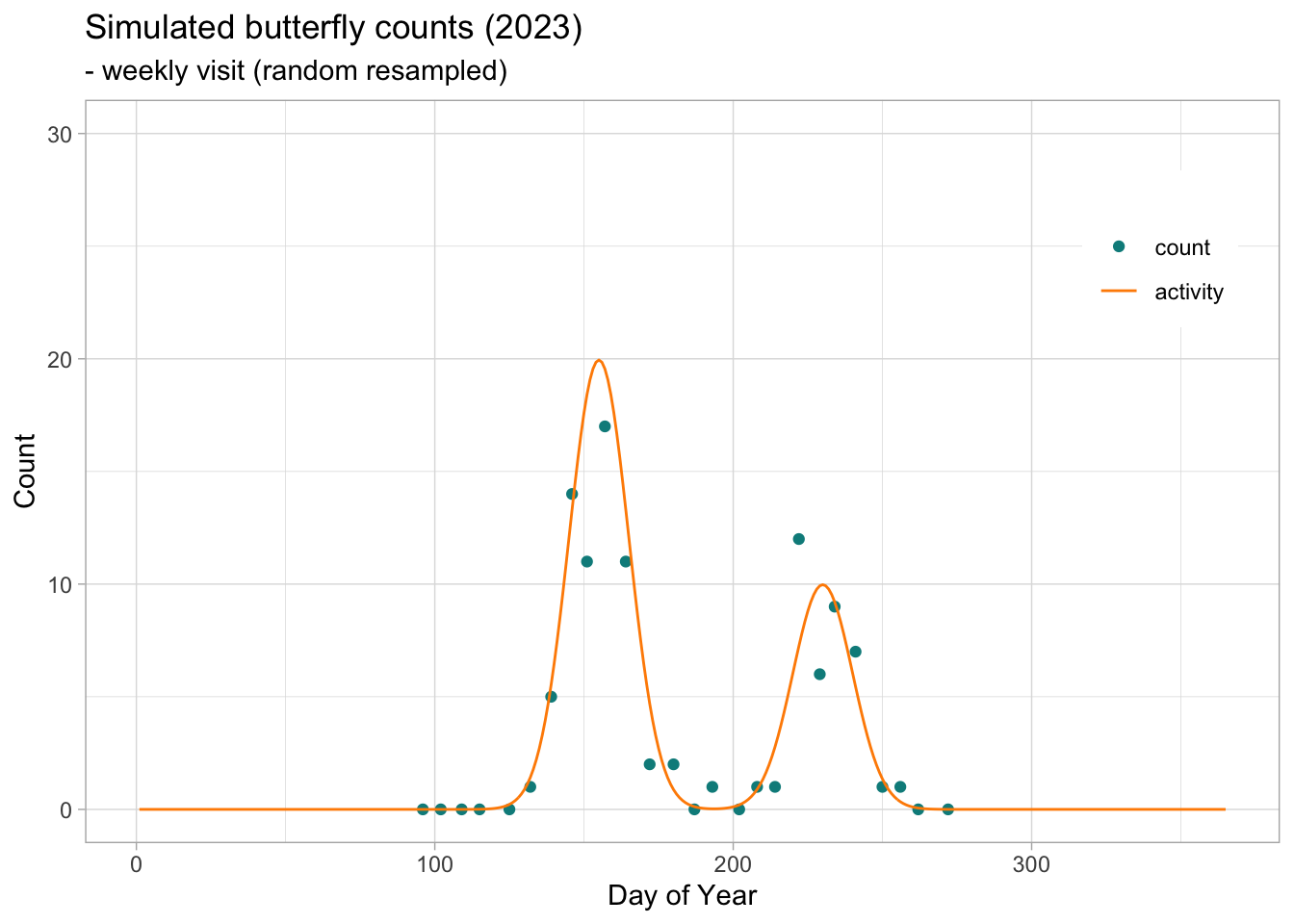
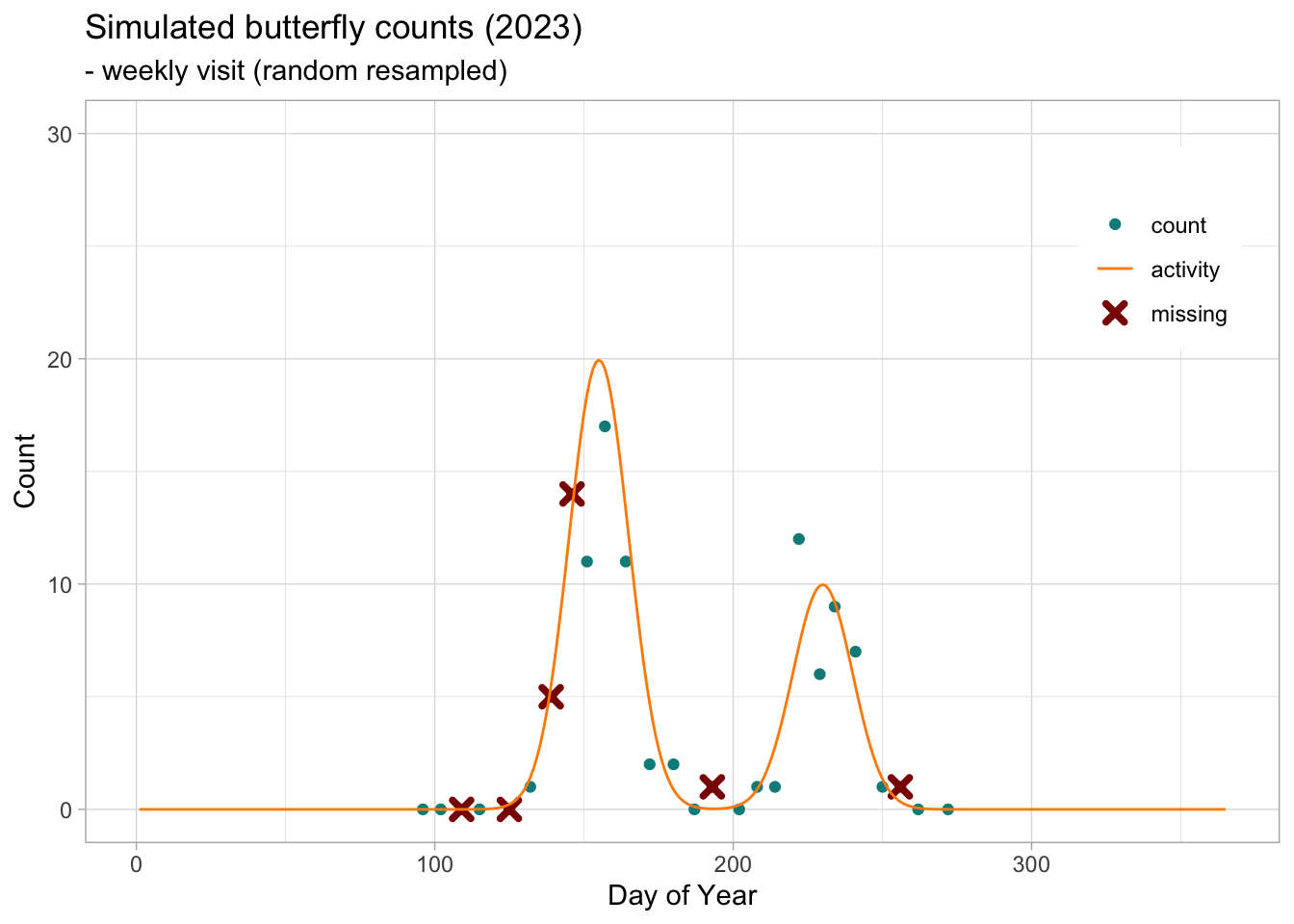
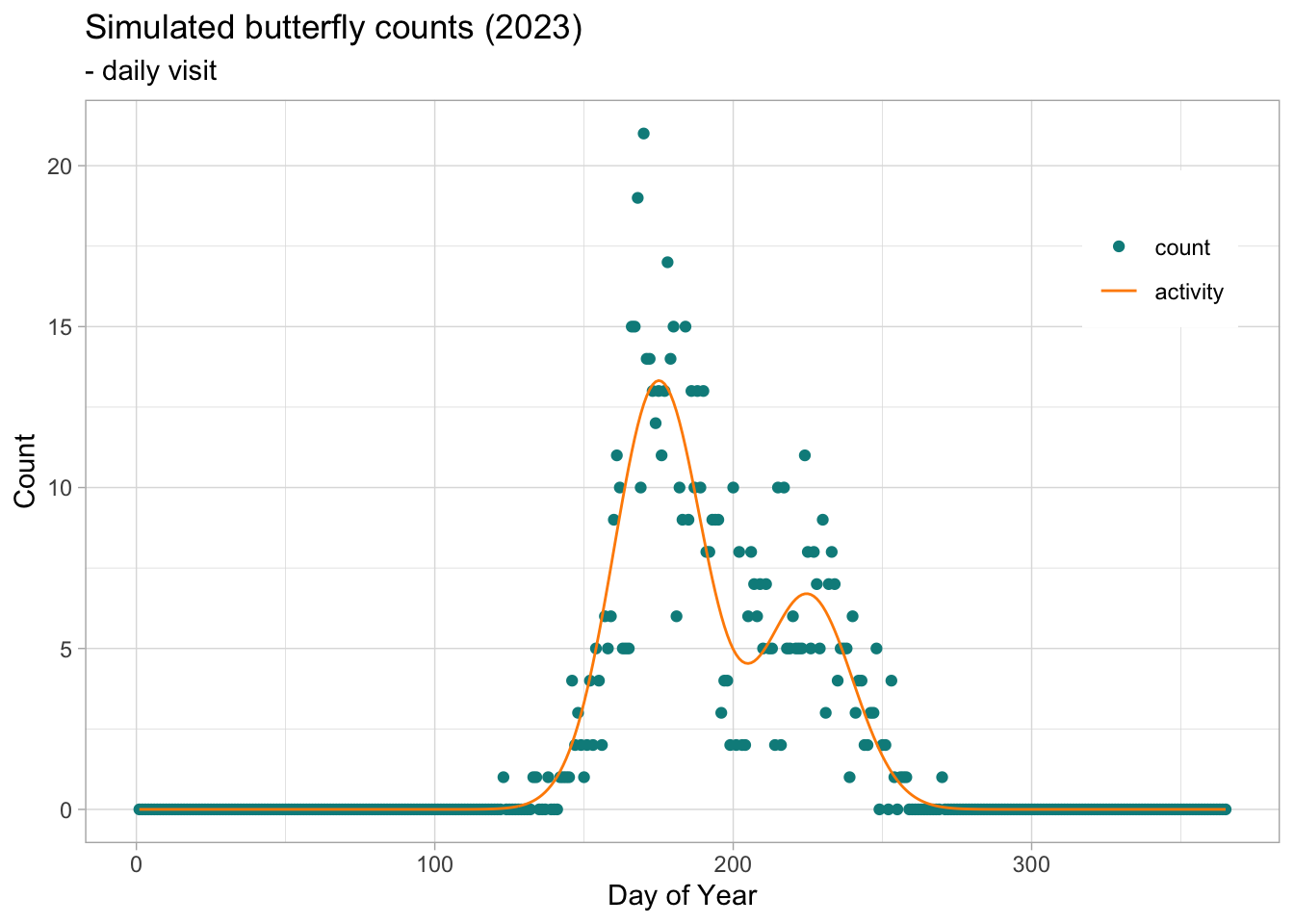
Some butterfly species produce more than one generation per year. This mean that the populations will produce successive generations within the monitoring season. This phenomenon will be reflected in the adult count, resulting in bimodal distributions when the two generations are sufficently spaced in time and that the overlap of the flight curve of the different cohort is not to large.
We can simulate bivoltine counts by simply overlapping two generation simulated independently, each with their specific parameters.
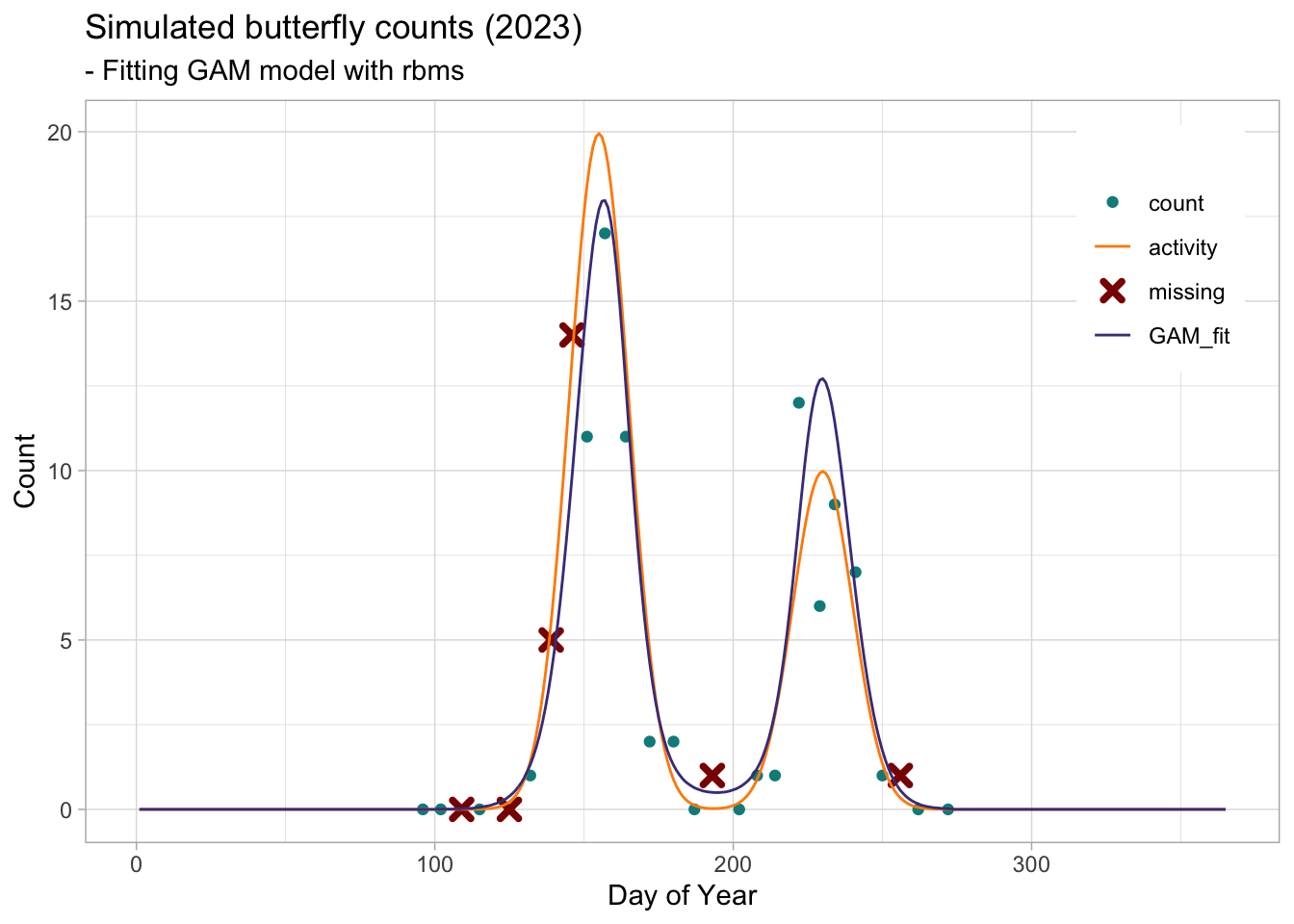
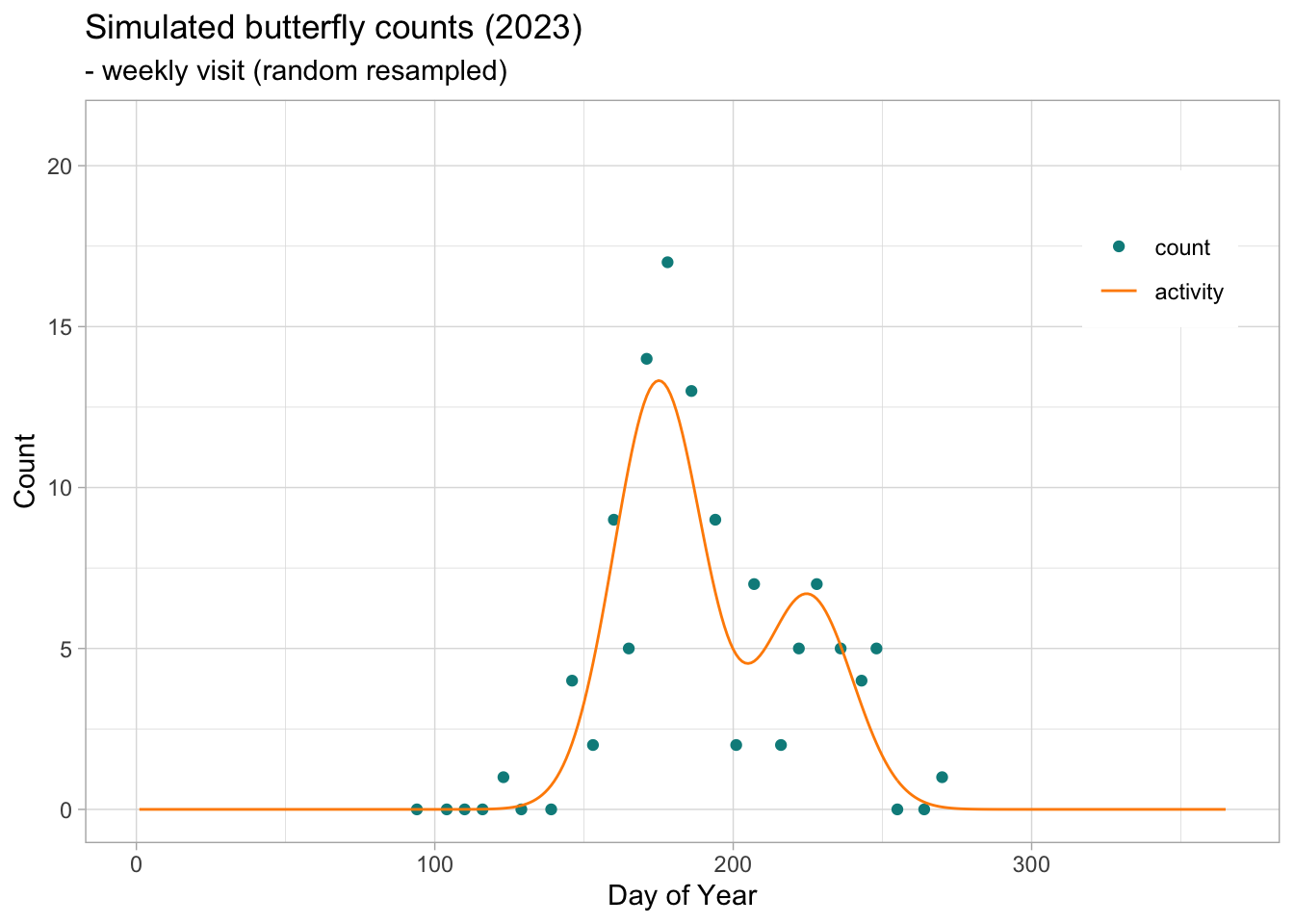
From the weekly counts recorded (simulated) for the bivoltine species, we can use the rbms package to fit a Generalized Additive Model (GAM) to retrieve the overall shape of the annual flith curve. Althouhg we only use one site here, this can be extended and more powerfull if we had more than one site monitored within the region.
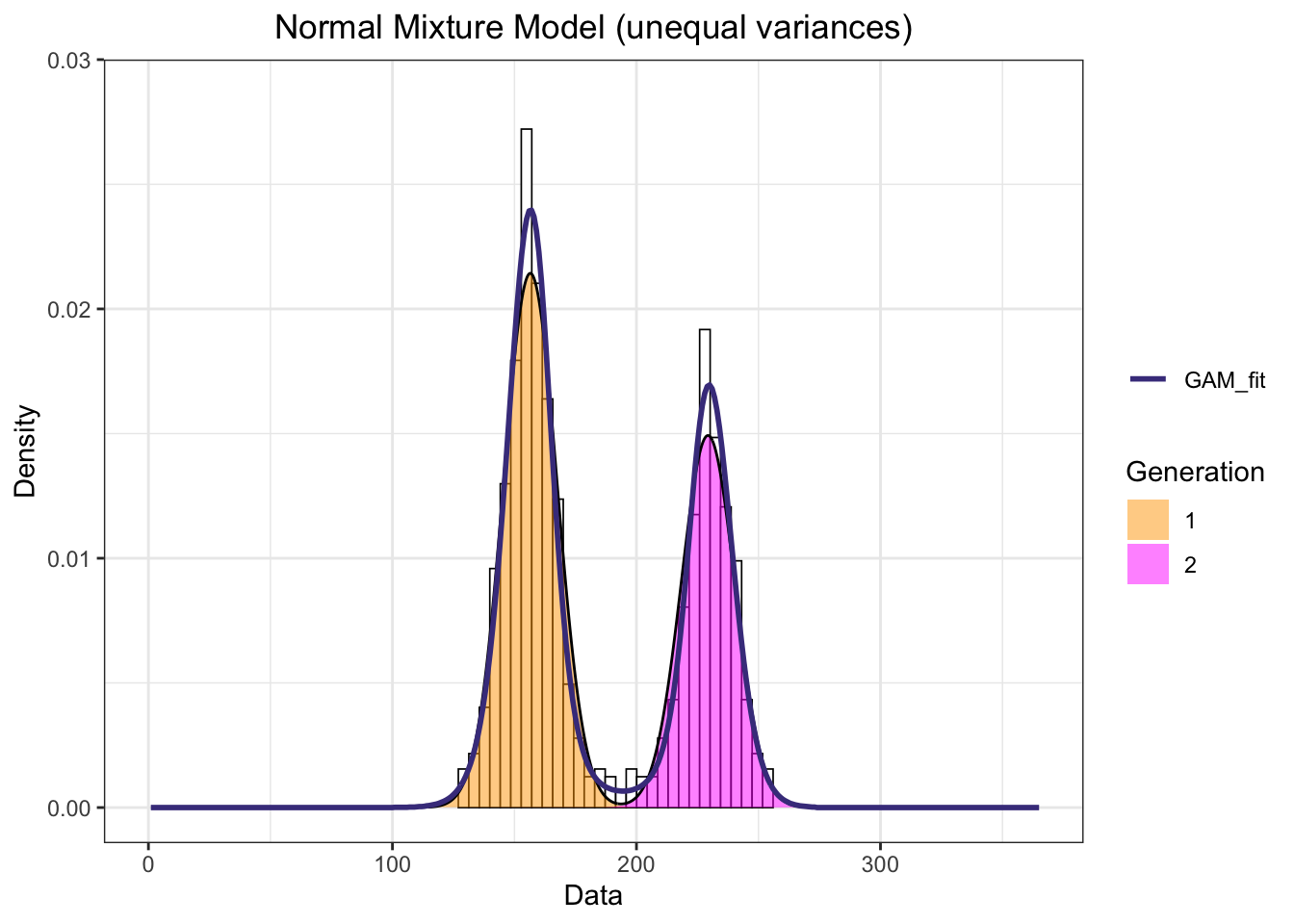
The GAM fitted very well the cummulative fligth curve (e.i., two generations activity curves). While the GAM returns the overall shape resulting from all observation the model does not distinguish the different generations. We can however fit a mixture model with k components (generations) to estimate and retrieve the parameters of the different generations. Here we will simply try to fit two generation with parameter of a Gaussian distribution (mean and standard deviation). The R package mixR provides an efficient algorithm (C++) to fit and assess the goodness of fit of such model(Yu 2022) .
Code
set.seed(102)btnbr <- pheno$NM*btfl_ts[,unique(abund.true)]x1 <-rep(1:365, round(btnbr))# fit a Normal mixture model (unequal variances)mod1 =mixfit(x1, ncomp =2)gen_plot1 <-plot(mod1, title ='Normal Mixture Model (unequal variances)')gen_plot1 +xlim(0, 365) +scale_fill_manual("Generation", values=c("orange","magenta")) +geom_line(data = pheno, aes(x = trimDAYNO, y = NM, colour ="GAM_fit"), lwd =1) +scale_colour_manual("", breaks ="GAM_fit", values = GAM_col)
Code
mod1
Normal mixture model with 2 components
comp1 comp2
pi 0.5909181 0.4090819
mu 156.4979230 229.3178504
sd 11.0005338 10.9353467
EM iterations: 7 AIC: 6756.14 BIC: 6779.26 log-likelihood: -3373.07
Parameter
simulation
Estimated (mixture)
generation 1 relative size
0.6666667
0.59
generation 1 peak
155
156
generation 1 sd
10
11
generation 2 relative size
0.3333333
0.41
generation 2 peak
230
229
generation 2 sd
10
10.94
The mixture model converged and indicate that the first generation is 0.59 percent and the second 0.41 percent, in other words, generation one has 1.44 the number of individuals of generation two. The peak of the first generation is located at day 156 and the second at day 229, with standard deviation of 11 and 10.94 respectively.
These results compare nicely with the parameters used in our simulation where the first generation had 500 individual, with a peak at day 155 and a standard deviation of 10, and the second generation had 250 individuals with a peak at day 230 and a standard deviation of 10.
We can see that the GAM fitted a cummulative fligth curve (e.i., the two generations activity curves) without distinguishing the two generations very well. We can try to retrieve the generation by fitting a mixture of k components (generations) defined by a Gaussian distribution.
Code
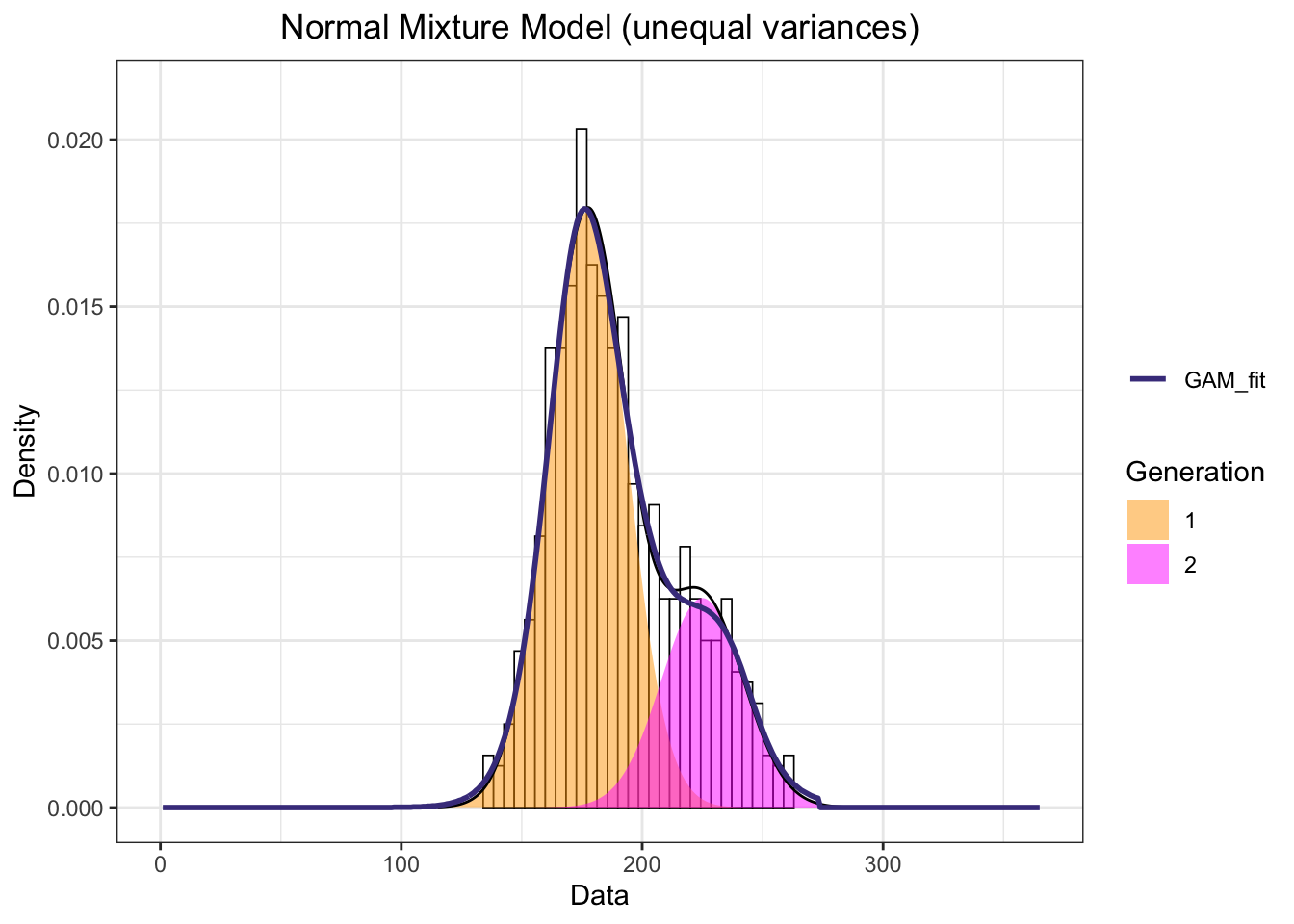
set.seed(102)btnbr <- pheno$NM*btfl_ts[,unique(abund.true)]x1 <-rep(1:365, round(btnbr))# fit a Normal mixture model (unequal variances)mod1 =mixfit(x1, ncomp =2)gen_plot2 <-plot(mod1, title ='Normal Mixture Model (unequal variances)')gen_plot2 +xlim(0, 365) +scale_fill_manual("Generation", values=c("orange","magenta")) +geom_line(data = pheno, aes(x = trimDAYNO, y = NM, colour ="GAM_fit"), lwd =1) +scale_colour_manual("", breaks ="GAM_fit", values = GAM_col)
Code
mod1
Normal mixture model with 2 components
comp1 comp2
pi 0.7312038 0.2687962
mu 177.1682929 224.9959818
sd 16.3513803 17.0979745
EM iterations: 141 AIC: 6920.48 BIC: 6943.54 log-likelihood: -3455.24
Parameter
simulation
Estimated (mixture)
generation 1 relative size
0.6666667
0.73
generation 1 peak
175
177
generation 1 sd
15
16.35
generation 2 relative size
0.3333333
0.27
generation 2 peak
225
225
generation 2 sd
15
17.1
The mixture model converged and indicate that the first generation is 0.7312038 percent and the second 0.2687962 percent, in other words, generation one has 2.7202908 the number of individuals of generation two. The peak of the first generation is located at day 177.1682929 and the second at day 224.9959818, with standard deviation of 16.3513803 and 17.0979745 respectively.
Yu, Youjiao. 2022. “mixR: An r Package for Finite Mixture Modeling for Both Raw and Binned Data.”Journal of Open Source Software 7 (69): 4031. https://doi.org/10.21105/joss.04031.